A Backup Model Is Not an Agent Continuity Plan
After Fable/Mythos, the enterprise AI question is not only which model to use. It is where the agent's business logic lives.
TL;DR: A backup model preserves capacity. It does not preserve behavior. If approval rules, thresholds, exceptions, and business context are buried in prompts and workflow glue, every model switch becomes a requalification project. Agent continuity requires an Operational Ontology and a Decision Runtime outside the model.
Anthropic said it received a US government export-control directive requiring it to suspend access to Fable 5 and Mythos 5 for any foreign national, including foreign-national employees inside the United States. To comply, Anthropic said it had to disable both models for all customers. Access to other Anthropic models was not affected.
The immediate reaction is predictable: enterprises will ask whether they need more model redundancy, from European models and open-weight models to self-hosted deployments, private models, and multi-model routing strategies. They probably do.
But a backup model is not an agent continuity plan. A backup model preserves capacity; it does not automatically preserve behavior. If a production agent depends on one model and that model becomes unavailable, switching to another model is only the visible part of the problem. The harder question is: what needs to be revalidated before the agent can safely act again?
If the answer includes prompts, tool instructions, workflow logic, exception handling, approval rules, risk thresholds, and business context, then the enterprise does not yet have a portable agent architecture. It has model-dependent automation.
What AI agent continuity means
For enterprise AI agents, continuity is not only uptime. It is the ability to preserve authorized behavior when the model, vendor, orchestration framework, or deployment region changes. The agent may use a different model, but it should still apply the same policies, thresholds, exceptions, approval paths, and audit requirements.
That is why AI agent reliability cannot be reduced to model availability. A continuity plan needs portable business logic, pre-execution control, and traceable decisions. In practical terms, this means the company needs a reusable operating model and a runtime that can evaluate every proposed action before it executes.
Business logic cannot stay buried in prompts
Enterprise agents are not just better chatbots. They are expected to act across real systems: CRM, ERP, ticketing, billing, procurement, support, legal, HR, internal knowledge bases, and legacy tools. A model can reason and tools can execute, but enterprise behavior depends on something more specific:
- who can do what;
- in which context;
- under which policy;
- with which exception;
- for which customer;
- in which region;
- above which threshold;
- with which escalation path;
- with which audit trail.
Today, too much of that logic is buried in prompts, workflow glue, product-specific configurations, and human judgment. That can work for demos, but it breaks in production. It also breaks when the model changes, because when business logic lives inside model-specific prompts or fragile orchestration code, every model switch becomes a requalification project.
Prompt-level guardrails can reduce obvious mistakes, but they do not make business logic portable across models. For that, the rules need to exist outside the prompt, in a form a runtime can evaluate consistently.
The agent may still have tools. But does it still know how the company makes decisions?
The durable asset is the Operational Ontology
The real issue is not model versus no model. The issue is where the company's operational knowledge is represented. In most enterprises, that knowledge is scattered across policies, documents, tickets, approvals, contracts, exceptions, historical decisions, team habits, and legacy systems. It is not clean, centralized, or reliably machine-readable. Yet this is exactly what agents need in order to act reliably.
This is where an Operational Ontology becomes strategic.
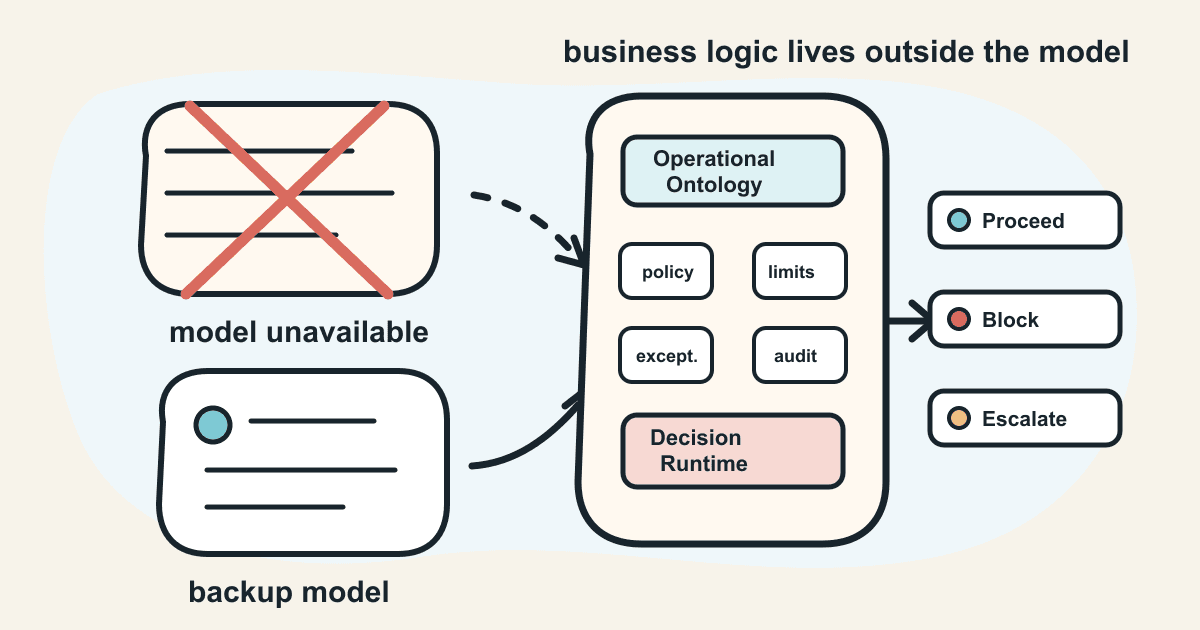
An Operational Ontology is not a workflow diagram, a static knowledge base, or a prompt. It is a structured, living representation of how the company actually operates: the rules, entities, roles, exceptions, decisions, constraints, and escalation paths that determine whether an action makes sense.
Once this exists, the model no longer has to carry the company's operational logic inside its context window. The model can propose. The Decision Runtime can evaluate. The enterprise can trace. That is the architecture shift.
In Rippletide's architecture, that portable logic is structured through Automatic Ontologies and made usable by agents through the Context Graph for Agents.
Example: the refund that is not just a refund
Take a simple case: a customer asks for an exceptional refund. An agent can read the policy, access the CRM, check the contract, open a ticket, and trigger a payment workflow. But the real question is not whether the agent has the tool. The real question is whether this refund should happen.
Does the contract override the standard policy? Has this customer already received an exception? Is the region regulated? Is the refund above a finance threshold? Is there an open legal dispute? Is this a VIP account? Did a similar case require escalation last month?
This is not solved by a better tool call. It is solved by representing the company's operational logic explicitly, then evaluating the agent's proposed action against it before anything happens in production.
That is the role of the Decision Runtime:
take a proposed action, evaluate it against the Operational Ontology, and return a controlled decision: proceed, block, escalate, or ask for approval.
This is very different from observing what happened after the fact. It is decisioning before action.
Model redundancy vs agent continuity
Model redundancy answers one question: can the system still call a model? Agent continuity answers a harder one: will the agent still behave according to the company's operational logic?
That means:
- approval rules are portable;
- exceptions are explicit;
- audit trails stay consistent;
- escalation paths do not have to be rebuilt;
- model switches do not require the agent to relearn how the company works.
Model redundancy is useful infrastructure. Agent continuity is operational architecture.
This is also why monitoring alone is insufficient. By the time a monitoring layer detects a bad action, the refund may have been issued, the email may have been sent, or the record may have been changed. Agent continuity depends on pre-execution enforcement, not only after-the-fact observation.
Why workflows alone are not enough
Workflow platforms describe how work is supposed to happen. Agents operate in the messy reality of how work actually happens. They face exceptions, cross systems, combine context, interpret ambiguous requests, and move between happy paths and edge cases.
A workflow can encode a process. An Operational Ontology captures the decision context behind the process. That distinction matters. If all the enterprise has is workflow logic, each new agent deployment becomes another custom services project. If the enterprise has an Operational Ontology, agents can reuse the same operational understanding across models, tools, and use cases.
This is what makes agent behavior portable.
Not portable in the abstract. Portable in the practical sense:
- easier to switch models;
- easier to test behaviors;
- easier to audit decisions;
- easier to explain actions;
- easier to deploy the next agent without rediscovering the company from scratch.
Fable/Mythos is a continuity warning
The Fable/Mythos event will push many companies toward model redundancy. That is reasonable. But the deeper lesson is about continuity. If model access can change overnight, enterprises should not let their agent behavior be trapped inside any one model, vendor prompt stack, or orchestration layer.
The model should be replaceable. The company's operational logic should not be.
The next strategic control point in enterprise AI will not simply be model access. It will be the ability to turn enterprise operations into reusable, executable, auditable agent behavior. That is what allows an agent to keep acting correctly when the model changes: not because the new model is identical, but because the company's operational truth lives outside the model, in a form the agent stack can use.
The real enterprise AI question
After Fable/Mythos, the question is not only: which model should we trust? It is: where does our agent's business logic live?
If it lives in prompts, it is fragile. If it lives in workflows only, it is incomplete. If it lives in people's heads, every deployment becomes consulting. If it lives in an Operational Ontology and is applied through a Decision Runtime, it becomes reusable infrastructure.
At Rippletide, this is the problem we are working on: turning messy enterprise operations into Operational Ontologies, then applying them through a Decision Runtime so agent actions are contextual, controlled, and traceable before execution.
Because when the model changes, the agent should not have to relearn how the company works.
Related reading:
Frequently Asked Questions
AI agent continuity is the ability to preserve authorized agent behavior when the underlying model, vendor, orchestration framework, or deployment region changes.
No. A backup model helps with availability, but it does not make agent behavior portable if policies, approval rules, exceptions, thresholds, and business context are buried in prompts or workflow glue.
Model failover answers whether the system can still call a model. AI agent continuity answers whether the agent still follows the same business rules, approval paths, constraints, and audit requirements after the model changes.
The company's operational logic: who can act, under which policy, for which customer, above which threshold, with which escalation path, and with which audit trail.
An Operational Ontology is a structured representation of how a company operates: entities, roles, rules, exceptions, constraints, decisions, and escalation paths used to evaluate whether an agent action should proceed.
A Decision Runtime checks a proposed agent action against the Operational Ontology before execution, then returns a controlled decision such as proceed, block, escalate, or ask for approval.