What if you can’t afford Palantir agents?

A recent article described the “Palantir decision stack” Connecting Agents to Decisions which is composed of data, logic, action, and security.
This is a very strong framework that we adhere to, but it relies on a strong assumption: that you are building your agents and workflows from scratch within Palantir.
In reality, you may already have an agentic stack that has been built incrementally over time. However, you may still be seeking Palantir-level performance because your initial proofs of concept have stalled for months and only a small number of agents are functioning reliably at scale.
The question, then, is how to approach the Palantir stack without starting over from scratch.
1) Seeking exhaustiveness in workflow modeling is probably not the right idea
For complex workflows, deployments often take months and require teams of forward-deployed engineers to build the underlying ontology.
This is because every decision depends on its impact, which in turn requires modeling the company and its external environment as comprehensively as possible.
If some components are missing, the system cannot fully account for the consequences of its actions, and the resulting decisions may be incomplete.
If you do not have months ahead of you, a different approach is needed. Instead of seeking exhaustiveness in all possible workflow scenarios, it is more effective to think in terms of constraints.
This is particularly true for customer-facing workflows, where human behavior follows a long-tail distribution. In practice, this means there is an almost infinite number of possible inputs, each with a very low probability, making it impossible to anticipate every case in advance.
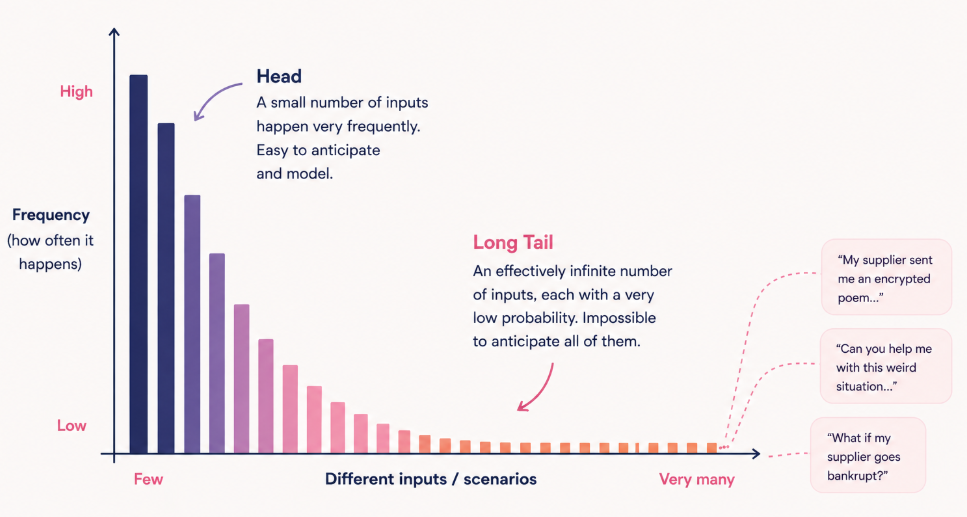
Thinking in terms of constraints leads to the introduction of a different paradigm: runtime enforcement.
2) Use runtime enforcement to combine agent autonomy and deterministic validation
The idea is to ensure that agents stay within a defined safety boundary while preserving their autonomy.
This introduces a distinction between micro and macro determinism. At the micro level, the agent adapts dynamically to each situation and input. At the macro level, it strictly adheres to company rules and defined instructions.
In this approach, data is not used to model every possible workflow in advance. Instead, it acts as a safety net that steers reasoning and enforces constraints at each step. This removes the need to seek exhaustiveness in a fully deterministic system.
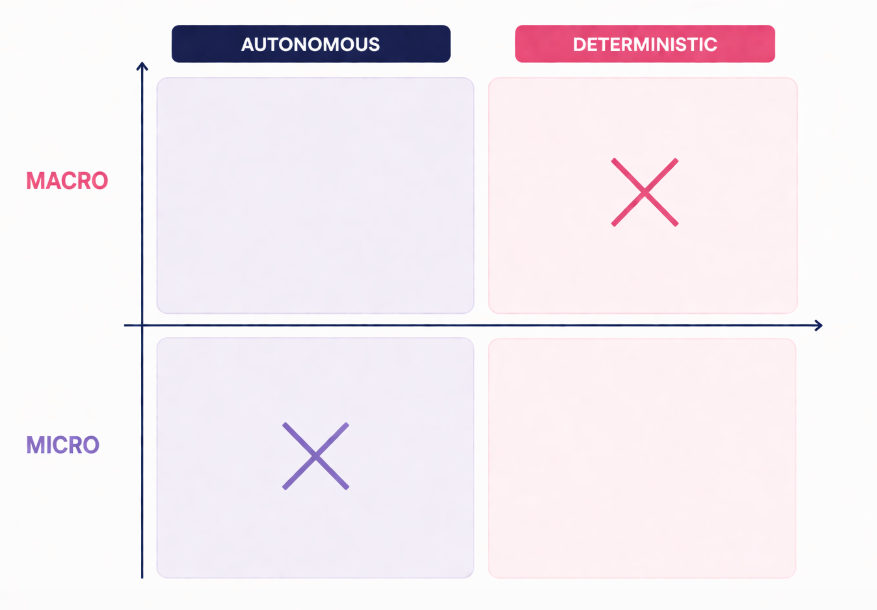
For more details, read Micro, Macro, and Multi-Determinism for AI Agents.
In practice, this means combining your existing agents and LLM with deterministic enforcement: you can bring the stack to an existing agent.
The interaction can be summarized simply: the LLM proposes, and the ontology validates.
See an example for Rippletide/dev when plugged into Claude Code:

Tip: strong enforcement early in the process ensures that you do not waste tokens following paths that fall outside guidelines. Early guidance saves tokens.
Try it here: Rippletide/dev
3) How to get closer to a Palantir agent over time: non-regressivity for more determinism
As a result of the previous step, your agent continuously learns by compounding on the data it sees and the decisions that are approved or rejected.
However, you need to make sure that once the system has done something correctly, it remembers it for the next time. This is what we call non-regression.
We introduced this concept in more detail here: Self-learning, non-regressive agents.
Along the way, your agent exhibits more deterministic, and therefore more predictable, behavior.
For example, in a customer support use case, once you introduce non-regression, the percentage of tickets solved does not decline on existing data. Once the system has learned how to close a ticket by satisfying a user for a given set of inputs, such as the question, user metadata, and history, it can reproduce the same sequence of actions for similar tickets.
When the data changes, for example when a new product is added to the catalog, the system leverages its learning capability to adapt. Once the new behavior is validated, it becomes deterministic again.
4) What happens when you have multiple agents, and one is not from Palantir?
In practice, you want agents to coordinate and sometimes cooperate to achieve a shared goal.
There are two dimensions to share:
- Data and knowledge
- Intelligence, meaning the models themselves
Recent discussions, including the latest a16z article, highlight parametric learning approaches, which consist of modifying model weights.
However, this does not work well for multi-agent systems. You cannot realistically embed relationships between agents directly into the weights of each model.
This leads to another approach: sharing knowledge between agents.
If one agent is not built within Palantir, how can it understand the Palantir ontology?
This is where runtime enforcement becomes critical again. It enables alignment through constraints rather than requiring a shared internal structure.
In practice, this means building a thin ontology overlay on top of the data, allowing you to index information and define policies in a way that all agents can comply with.
5) Automated harness creation to keep agents updated
The beauty of automatic ontologies is that they allow you to create agent harnesses quickly and at low cost. This means you can always provide the most up-to-date and best-suited harness for each agent.
Here is one observation we made while benchmarking harness creation. Full article here.
GPT-5.2-Codex performed better than GPT-5.3-Codex on policy-following tasks in the week after Codex 5.3 was released. This might seem surprising at first. However, the explanation is simple: Codex 5.3 was still using a harness designed for version 5.2. Because the harness had not yet been updated, the newer model performed worse.
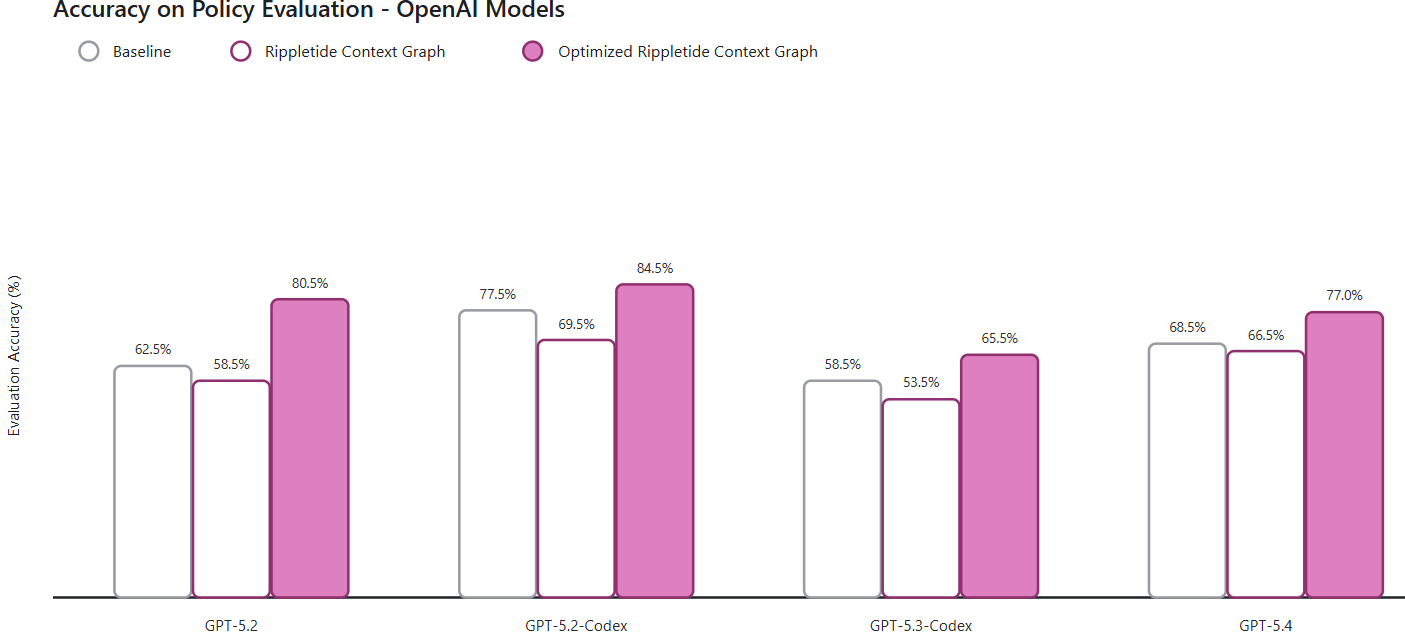
This highlights how critical the harness is in guiding model behavior, especially for keeping agent performance consistent over time.
I’m happy to compare notes with teams working on enterprise harnesses.
What’s next?
The next step is to reduce latency so runtime enforcement overhead becomes negligible. At Rippletide, we observe less than 100 milliseconds of overhead for the vast majority of use cases.
Want to deploy Palantir-level agents? Book a demo.