Self-Learning, Non-Regressive Agents

From exploration to compounding intelligence
Introducing Self-Learning, Non-Regressive Agents
Self-learning agents are often described as the natural evolution of large models. The real shift is not from static models to learning models, but from episodic improvement to non-regressive compounding. Intelligence does not scale if it forgets.
1. Why agents do not scale today
Most agents today are trained offline. They are pretrained, sometimes fine-tuned, and then deployed. Once deployed, they run on frozen parameters and were tested in duplicate environments that were with an old scaffolding (code around the agent execution: tools, memory and workflows). Once deployed in production those agents encounter far richer and more diverse information than they ever saw during training.
For example, new questions seen in production but never seen during training. Few chances for an LLM-based agent to react correctly.
Production is treated as inference. Learning is treated as a separate phase.
The most valuable information an agent encounters is observed while it is running: edge cases in customer conversations, unexpected combinations of constraints, rare failures, new task variations. Yet most systems do not structurally integrate this signal. Instead, teams rely on prompt iteration or periodic retraining.
Prompt iteration is not structural learning. It is a surface adaptation.
As Andrej Karpathy puts it in his podcast with Dwarkesh Patel, "anything that happens during the training of the neural network, the knowledge is only a hazy recollection of what happened in training time. That’s because the compression is dramatic. You’re taking 15 trillion tokens and you’re compressing it to just your final neural network of a few billion parameters. (...) Whereas anything that happens in the context window of the neural network (...) is very directly accessible to the neural net." So the most valuable information an agent encounters is observed while it is running: edge cases in customer conversations, unexpected combinations of constraints, rare failures, new task variations. Yet most systems do not structurally integrate this signal. Instead, teams rely on prompt iteration or periodic retraining.
Sam Altman has suggested that we will reach AGI when models understand when they do not know something and autonomously learn the missing task or knowledge gap. This statement highlights the real bottleneck. Scaling intelligence is not only about generating better outputs but is about recognizing uncertainty and closing capability gaps without external orchestration.
Reinforcement learning in production changes the equation. Once an agent scaffold exists, reproducing learning loops becomes inexpensive. What remains costly is the environment: the real-world feedback, the simulator, the structured evaluation signal that determines whether a trajectory is valid. In other words, generation becomes cheap, but meaningful evaluation remains scarce.
Today’s agents generate continuously but do not compound. They encounter novelty, but they do not structurally accumulate mastery from it. As a result, they improve episodically rather than continuously and fail over and over on new unseen tasks.
2. The promise of self-learning agents
A self-learning agent does not simply execute tasks. It accumulates capabilities over time.
Recent research from ETH Zurich and MIT on Sequential Distillation for Continual Learning illustrates that this goal is attainable. They use a simple Teacher-Student architecture using the same model, where the Student receives a query, and the Teacher receives the query + a demonstration. Naturally the Teacher distribution is better from a truth-seeking perspective. They then minimize the reverse KL divergence between the Teacher and Student to pull the Student distribution closer to the Teacher's. To ensure the teacher evolves alongside the student to track its progress, they also update the teacher's weights using an exponential moving average of the student's parameters.
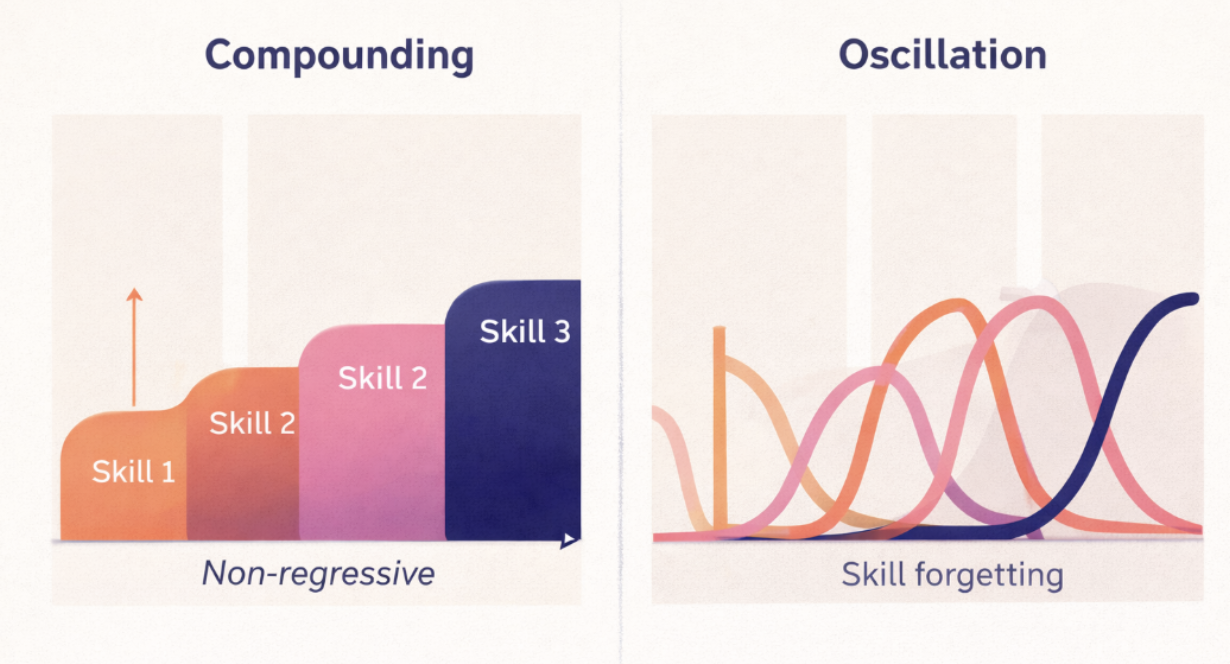
They test this method on the task of learning new skills sequentially. This problem with classic supervised fine-tuning usually leads to oscillations, i.e. the model forgetting the last skill when starting to learn the next one. But their method achieves non regressive learning of new skills : the student trained sequentially on different skills managed to master them each without forgetting the precedent.
Two properties are essential in this result. First, the model learns largely from its own behavior, effectively acting as its own teacher. Second, the distillation process prevents newly acquired skills from overwriting previously learned good behavior.
This distinction is fundamental. Self-learning without safeguards leads to oscillation. Self-learning with non-regression leads to compounding.
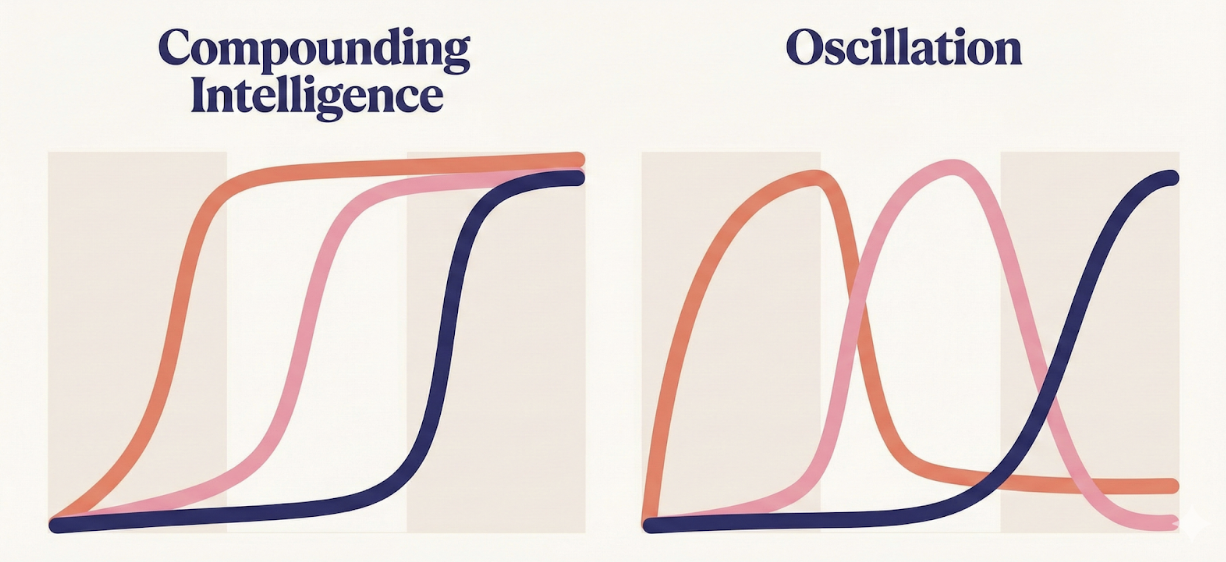
And in the end the skills compound:
Exploration at scale becomes meaningful only if knowledge persists. Consider a customer support agent encountering a request it has never seen before. The agent can simulate multiple response strategies, evaluate their effectiveness, and identify a trajectory that satisfies the constraints of the interaction. If this successful trajectory is integrated into the system’s repertoire without degrading prior skills, the agent’s capability surface expands.
This is analogous to how Nvidia enables robots to “dream” in simulation in order to explore new tasks before physical deployment. The system generates candidate behaviors, evaluates them in a safe environment, and integrates only the validated improvements. Exploration becomes a controlled search over trajectories rather than a blind expansion of possibilities.
We have also seen examples in scientific domains where generative systems propose numerous hypotheses. The breakthrough does not emerge from generation alone, but from the selective reinforcement of promising directions.
Self-learning agents unlock a new regime: they do not simply respond to novelty; they transform novelty into durable skill.
3. Non-regression as a key enabler: Neuro-Symbolic AI
Combining neuronal and symbolic parts
Compounding requires a strong guarantee: once a capability is validated, it must not silently degrade. This is the principle of non-regression.
In practical terms, this means that when an agent discovers a trajectory that reliably succeeds for a defined set of parameters, that trajectory should be frozen. Freezing does not imply that exploration stops. It means that validated policies become part of a stable substrate on which further exploration can build.
Some use what they call “Neuro-Symbolic AI”: that means combining a neuronal part such as Reinforcement Learning for explorations and Symbolic parts. The symbolicism can bring a non-regressive aspect to agents.
This introduces a form of macro-determinism. At the micro level, agents can explore stochastic trajectories in simulation. At the macro level, the system maintains a stable set of validated behaviors that are protected from accidental degradation. This is the same principle as Neuro Symbolic AI.
Some Maths behind
In reinforcement learning, the mathematical foundation for "non-regressive" learning (where each new policy is guaranteed to be at least as good as the previous one) is rooted in the Policy Improvement Theorem.
At its core, this theorem relies on the Bellman Operator being a contraction mapping in a complete metric space. When we evaluate a policy π to find its value function Vπ, and then update to a new policy π′ by acting "greedily" (choosing the action that maximizes the expected return based on Vπ), the math dictates that Vπ′(s)≥Vπ(s) for all states s. This creates a monotone improvement property.
In modern AI, this theoretical ideal is approximated through Trust Region methods like TRPO or PPO. These frameworks translate the abstract Bellman improvement into a practical constraint: they mathematically bound the "distance" (often using KL divergence) between the old and new policies. By staying within this "Trust Region," the agent ensures that the update to the neural network remains in a zone where the policy improvement is theoretically guaranteed, effectively preventing the agent from "regressing" or forgetting vital behaviors while it integrates new information.
Non regressivity is even more important for multi agents
In multi-agent systems, this stability becomes even more critical. Transfer learning between agents, shared scaffolds, and evolving internal tools can amplify both improvement and failure. If an agent is allowed to modify its own harness or internal mechanisms without guardrails, it can also degrade itself. In principle, an agent can rewrite components that previously ensured reliability.
Projects such as OpenClaw illustrate both the promise and the limitations of current systems. Agents that understand their harness can modify and improve it to a certain extent. However, there is no inherent guarantee that such modifications are monotonic improvements. Without structural safeguards, self-modification introduces the risk of self-degradation.
The potential value of making agents self-degradation-proof is substantial. It converts exploration from a risky endeavor into a bounded optimization process. When Peter Steinberger mentions security as a next focus area, one interpretation is that ensuring agents cannot undermine their own guarantees becomes a central engineering challenge. Non-regression is not only about performance; it is about integrity.
To compound learning, the system must guarantee that validated trajectories remain valid unless explicitly superseded by demonstrably superior ones.
4. Evaluation as the bridge between generation and compounding
Generative systems can produce a vast number of candidate solutions to any given problem. The limiting factor is not imagination, it is rather selection.
If an agent explores many trajectories, only a subset will be robust, generalizable, and aligned with long-term objectives. The role of evaluation is to distinguish promising directions from noise. This new way to develop AI systems is similar to how genetic algorithms (GAs) were treated.
For example during the OpenAI hackathon we illustrated this on scientific discoveries. One can approximate this process using citation-style structures. Hypotheses that are repeatedly referenced and supported by other findings gain weight. Hypotheses that remain isolated or contradictory lose weight. PageRank-style mechanisms provide a structural way to prioritize ideas based on relational reinforcement rather than intuition.
The same principle applies to agents.
Evaluation operates at two levels. At the micro level, the system assesses outputs: did the response satisfy constraints, did the action complete the task, did the trajectory remain within safety boundaries? At the macro level, the system assesses outcomes: did the behavior improve long-term performance, did it generalize across similar contexts, did it preserve previous capabilities?
Freezing trajectories requires strong evaluation. The system must define what constitutes success for a given parameter set, and it must ensure that integrating a new trajectory does not degrade existing validated behaviors.
Large-scale generation without structured evaluation leads to drift. Large-scale generation with structured evaluation leads to compounding.
From learning to compounding
Self-learning agents are not simply agents that update their weights in production. They are systems that explore new trajectories, validate them against structured criteria, and integrate them without regressing on prior capabilities.
The architecture is simple in principle:
-
Explore new trajectories in controlled environments.
-
Evaluate them rigorously at both micro and macro levels.
-
Freeze validated trajectories for defined parameter regimes.
-
Continue exploration on top of a stable substrate.
Without non-regression, self-learning becomes unstable experimentation and it becomes cumulative progress.
The future of agents is not only about generating more possibilities. It is about ensuring that every validated improvement remains part of a growing, reliable foundation.
Want to start?