Micro, Macro, and Multi-Determinism for AI Agents
Co-authored with Guilhem Loussouarn, PhD, Imperial College London
A key property often sought in reliable systems is reproducibility: when faced with the same input, they should deliver the same output. For AI agents, reproducibility and predictability are key drivers of trust and adoption. Agents must adapt to new contexts, coordinate multiple steps, and sometimes collaborate with other agents, tasks that benefit from flexibility but complicate predictability. This creates a fundamental trade-off: how to preserve determinism for control, safety, and trust, while allowing enough variability for agents to remain effective in dynamic environments.
In a recent article, Mira Murati (former CTO of OpenAI) and Thinking Machine Lab's team delved into an interesting fact: asking twice an LLM (even with temperature 0) the exact same query doesn't produce the same result twice. The reason behind is not having batch invariance. Floating points approximations are performed in a different manner based on the size of the batch. They propose an elegant way to solve it, we won't discuss the solution here and assume it.
This definitely helps on explainability and predictability, but is far from enough to guarantee AI Agents reliability in large deployments. We'll show why with concrete real-life examples.
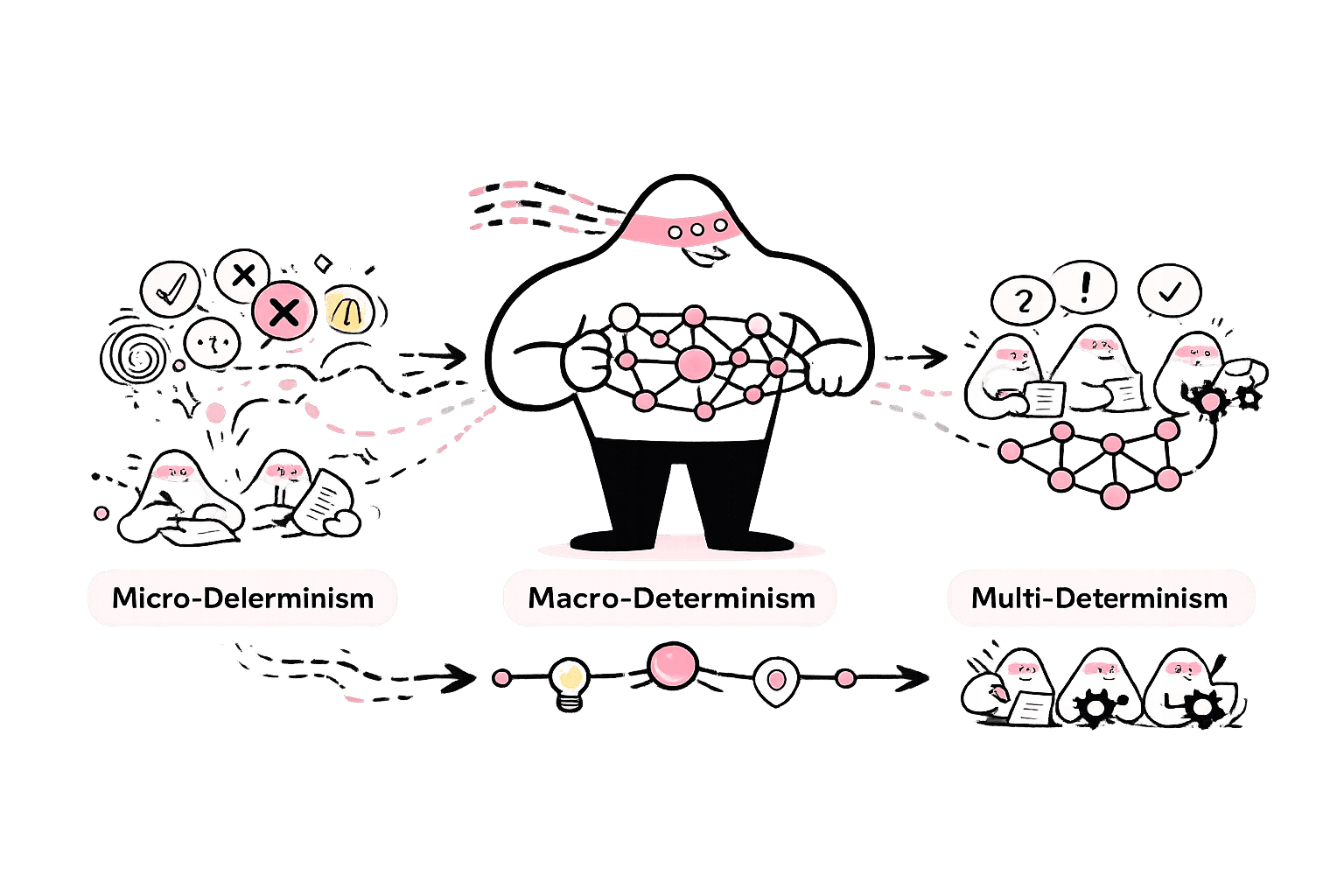
This article extends the discussion by distinguishing three layers of determinism in AI systems:
- Micro-determinism: stability at the level of individual tasks and outputs,
- Macro-determinism: consistency in agent orchestration and decision logic,
- Multi-determinism: an extension for multi-agents systems.
We argue that the future lies in combining deterministic stability with inference statistical learning to create self-improving but non-regressing agents.
Example 1: Deterministic Guardrail Enforcement
Mira Murati's method doesn't imply that defining guardrails (business rules) mean they will be followed deterministically. When for a Sales Agent the programmer defines guardrails such as "Don't talk about pricing during first call", it is expected to always apply, whatever the specific discussions.
Let's see why another level of determinism is needed.
If you keep the exact same prompt, the result is always the same: that is the result shown by Thinking Machine Labs, let's call it Micro determinism.
If you keep the exact same guardrails but change the question, sometimes the guardrail will be followed and sometimes not.
The guardrail doesn't apply deterministically.
Guardrails enforcement remains a challenge, and usually a barrier to deploy AI Agents in front of customers. Because of that, one of the largest US banks told us "never, ever I will deploy an LLM-based agent in front of a customer". Let's see further in the article how Rippletide addressed it.
A naïve approach would be to postcheck results: before displaying a result to a customer let's check if the rule has been applied. Rule based or regex is clearly not a solution, it has proven not to be maintainable, large players unsuccessfully experienced it;
Current evaluation methods such as LLM as a judge fall short when combining multi step processes. It often diverges by engaging on an erroneous path at a point, probability to falsely evaluate an LLM output compounding.

A good survey on LLM-as judge technique can be found here.
Example 2: Grounding Decisions
Let's see another example requiring another type of determinism than Micro.
That is a real example we encountered with a French luxury brand.
A user asks an AI Agent on the brand website "Which fond de teint (foundation) do you recommend me?" The agent performed steps 1) Ask customer skin tone 2) Browse catalog 3) Pick the latest foundation matching the skin tone.
By reproducing the same step with another customer asking "Which fond de teint (foundation) should I buy?" slightly different from the previous query but very close, the agent did 1) Browse catalogue 2) recommend a foundation. It did not even ask the skin tone of the customer and recommended without the information. For sure the recommendation was not grounded and the recommended foundation has little chance to suit the customer.
This shows determinism as Micro level is not enough for real AI Agents deployment and business requirements.
Here, an approach could consist of not letting the system answer until it has the correct elements to decide. Provided that the reasoning component uses it.
The Micro and the Macro Determinism
Murati's paper allows determinism on what we call "micro" level. Once we have a task it will execute it deterministically. I.e if replaying with the same input it will provide the same output.
But for agents, micro execution is one thing, those micro tasks are usually performed under the concept of an external call tool orchestrated at a higher level.
That means AI Agents would gain in bringing some determinism also at the orchestration level.
A higher level determinism would mean for example checking predicates are true before performing an action, always checking it, not probabilistically - deterministically.
Or not calling specific actions based on some logic.
We'll call this "Macro determinism".
Rippletide builds specific reasoning components based on these principles.
Do Micro and Macro Determinism Together Only Mean Fine-Grained Workflows?
At Rippletide we believe the best way to leverage determinism is non regressing Agents.
Nothing is more frustrating or anti production grade than a system that works once but regresses when a new information is added. Very frequent on LLM-based agents when fixing behaviours by iterating on a prompt
So where to put the beauty of statistics and learning capabilities of AI?
Yann's thesis is self improving agents that never regress.
That means bringing Reinforcement Learning and other statistical learning methods to explore spaces and options only when Agent is blocked. But once a solution works (evaluation) it becomes deterministic and thus brings control and predictability for next rounds.
It all relies on evaluation, the subject everyone is interested in right now.
Rippletide found a promising path - subject for a future article.
The formula can be summed up as:
deterministic stability + statistical learning → self-improving, non-regressing agents.
Multi-Agent Determinism: example in Telco
What happens when multiple agents work together?
One common issue with multi-agent systems is non stationarity (especially for MARL learning part), i.e the time dependance.
For example when systems rely on reinforcement learning, the policy related to agents initialisation usually depends on agents initialisation order. But in real scenario, if agents initialisation order change then the systems is much weaker
Let's illustrate with an example on communications for a Telco company.
Asynchronous communication and coordination leads to non-determinism:
- Messages can be delayed or lost leading to a different output from the system
- The message order can also have an influence on the output of the system
- In game theory multiple equilibrium can be reached for the same situation. MA systems do not derogate from the rule. It is not always possible to predict which equilibrium will be reached
Environment interaction, partial observability from agents and noise coming from the environment can lead to different output from the same system situation:
- Partial observability is a classical setup for MAS where each agent has his own local observation with some complementary information. Especially the environment can be approximate by non deterministic models
- The environment can also be non deterministic
- If one agent is non deterministic it contaminates the whole system
Bringing some determinism at multi agents level can definitely bring more control.
Communication networks are now considered critical infrastructures. A minimum quality of service must be guaranteed to prevent outages or blackouts. The introduction of AI agents to control different parts of the network promises significant optimization benefits such as reducing energy consumption and improving throughput. It also introduces risks related to loss of control and reduced understanding of system behavior. Standardization bodies like 3GPP and regulatory institutions are therefore calling for greater explainability and predictability of AI solutions before they can be deployed in critical components of the network. Ensuring a degree of determinism is one possible way to provide this control and transparency.
To support safe adoption, many telecom operators are developing digital twins of their networks. These digital replicas allow the testing and evaluation of different AI solutions in multi-agent system (MAS) scenarios under controlled conditions. A high-fidelity digital twin can reproduce network behavior with great accuracy, enabling researchers and operators to study agent decisions and assess their impact. If determinism is introduced into such simulations, their outcomes can be considered reliable proxies for real-world behavior. This, in turn, allows insights from simulations to be translated into actionable explainability and control in real network applications.
Conclusion
Through the examples of guardrails enforcement and ungrounded decisions we demonstrate the need for more determinism for AI agents reliability. We introduce the notion of "Micro, Macro and Multi" determinisms. Our thesis to create self-evolving but non regressing agents brings reliability, we demonstrated it in real-life AI Agents deployments.
Frequently Asked Questions
Micro-determinism (same input produces same output at task level), macro-determinism (consistency in agent orchestration and decision logic — e.g., guardrails always enforced regardless of query), and multi-determinism (predictable behavior in multi-agent systems despite asynchronous communication and partial observability).
Micro-determinism ensures the same prompt yields the same result, but guardrails defined as 'don't discuss pricing on first call' may not apply deterministically across different conversations. Real deployment requires macro-level consistency in decision logic, not just task-level reproducibility.
Agents that use deterministic stability combined with statistical learning to self-improve without regressing. Once a solution works (verified by evaluation), it becomes deterministic for future rounds while reinforcement learning explores only when the agent is blocked.
In multi-agent systems, if one agent is non-deterministic it contaminates the whole system. Asynchronous communication, partial observability, and environment noise can all lead to unpredictable outputs. Standardization bodies like 3GPP call for explainability and predictability before AI can be deployed in critical infrastructure.